Summary
More B2B buyers are now encountering brands through AI-generated responses when researching vendors and evaluating options. Yet no standardised measurement infrastructure exists for what those systems actually say. Brands have invested heavily in managing their search visibility and have decades of tooling to support it. For AI, that infrastructure does not yet exist.
This guide introduces the Generative Brand Mention Framework (GBMF), an open measurement specification for brand representation in AI-generated responses. GBMF comprises three measures. Each addresses a separable property of how a brand is represented when an AI system answers a category-relevant question.
Current approaches to AI visibility measurement have three problems. Most tools measure clicks and impressions, which do not apply to AI-generated responses. Where AI-specific scores do exist, they are generally proprietary: the methodology is not published, the prompt sets are not disclosed, and scores from different vendors cannot be compared. And most tools measure at most one dimension, whether the brand is mentioned, without capturing what is said or how the brand is characterised.
A brand that AI systems rarely mention needs to build visibility. A brand that AI systems frequently mention but frequently misrepresent needs to address alignment before further visibility investment. A brand that is mentioned accurately but characterised unfavourably needs sentiment work. In some cases, building more visibility before fixing the alignment problem makes things worse. MV, MA, and MS separate these problems so the right response can be identified.
This page summarises the guide — the full document is the PDF
Implementation steps, Brand Profile construction, prompt set rules, and evaluator requirements are in the PDF only.
Download the full guide (PDF) →The three measures
MV: brand-mention visibility
MV answers: how consistently does AI mention the brand across a standard set of queries relevant to its category?
A declared prompt set of 30 to 50 queries spans the types of questions buyers actually ask: “what are the best tools for X?”, “compare platforms for Y”, “what do teams use when they need to do Z?”. These prompts are run across the declared AI engines, with each prompt-engine pair queried multiple times to account for the natural variation in AI responses.
For each engine, the per-engine MV is the mean mention rate across the full prompt set. The headline MV is the equal-weighted mean of those per-engine scores. It sits on a 0 to 100 scale and is interpretable as an estimated mention probability: an MV of 52 means the brand appears in an estimated 52% of AI responses to category-relevant prompts, averaged across the declared engines.
Per-engine scores are always reported alongside the headline. Engine differences are systematic rather than sampling noise. A brand with a strong overall MV driven entirely by one engine has a concentration risk that the headline obscures.
Three companion statistics are reported alongside the headline MV: Reach (the percentage of prompts on which the brand is mentioned at least once), Intensity (per engine, the mean mention rate among prompts where that engine mentioned the brand; the headline is the equal-weighted mean of per-engine intensities), and Concentration (a Herfindahl-Hirschman Index over the prompt-level contribution shares). Together they describe the shape of a brand’s mention distribution.
MA: brand-mention alignment
MA answers: when AI mentions the brand, does it describe it correctly?
MA is measured against the Brand Profile, a structured document the brand provides. The Brand Profile specifies what is factually accurate at a given point in time: the primary product category, pricing entry point, key features, key use cases, named integrations, founding year, and disambiguation statements (for example, “this is not a CRM” or “this product is separate from the enterprise offering”). The Brand Profile is version-controlled.
The Brand Profile distinguishes three tiers of claims. Tier 1 covers externally verifiable facts (founding year, pricing, product category), which carry full weight. Tier 2 covers brand-stated operational facts (feature descriptions, use cases, named integrations), which also carry full weight. Tier 3 covers positioning claims (“best for enterprise”, “leading platform”), which are excluded from scoring entirely.
MA is computed only for responses where the brand is mentioned and where the response contains evaluable descriptive content. An MA of 67 means AI descriptions align with the brand’s declared facts 67% of the time on average.
MA coverage (the proportion of mentions that contain evaluable descriptive content) is reported alongside every MA score. A brand with most mentions as bare-name list inclusions has a different representational problem than one with high-coverage mentions.
MS: brand-mention sentiment
MS answers: when AI mentions the brand, does it speak positively or negatively about it?
MS measures sentiment directed toward the brand, not the overall tone of the response. A response that criticises the product category but singles out the brand approvingly is positive for the brand. A response that is generally favourable about the category but identifies the brand as a poor fit for certain users is negative for the brand.
MS is reported as three shares (% positive, % neutral, % negative) plus a net figure. The net is positive share minus negative share, on a -100 to +100 scale. A net of +25 means positive characterisations outnumber negative ones by 25 points of share.
The shares-plus-net structure matters. A net near zero may arise from uniform neutral coverage or from polarised coverage in which positive and negative characterisations both occur substantially. These are different brand situations and they call for different responses.
The Visibility-Alignment map
The featured diagnostic places every brand in a category on a Visibility-Alignment quadrant, with sentiment shown as point colour. Because every brand in a category is scored from the same collected responses, the map is a competitive comparison by default.
The quadrant boundaries sit at MV = 50 and MA = 50. These are presentation conventions, not thresholds that enter any computation. The underlying scores are continuous.
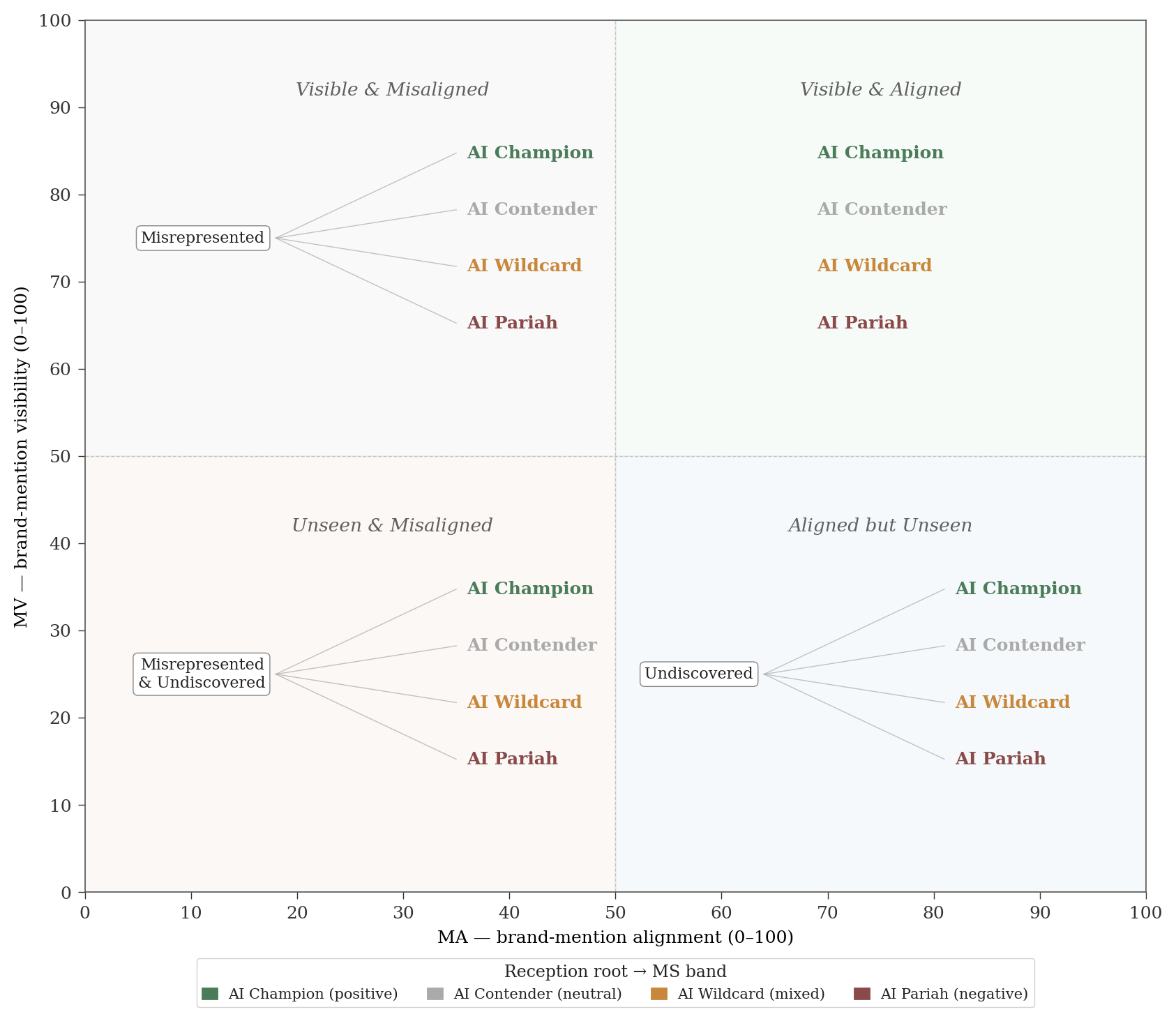
Each quadrant combines with a sentiment band to give a brand-representation state. The reception root names how the brand is received: AI Champion (positive), AI Contender (neutral), AI Wildcard (mixed), AI Pariah (negative). A position prefix names how the brand’s standing departs from the visible-and-aligned ideal: Undiscovered (accurate but unseen), Misrepresented (visible but inaccurately described), or both.
Visible & Aligned (high MV, high MA). The brand is mentioned broadly and described accurately. The work in the off-Champion states (Contender, Wildcard, Pariah) is positioning and sentiment-driver work, not fact correction.
Visible & Misaligned (high MV, low MA). Frequent mention with low accuracy. Remediation must precede further visibility investment. The field-level MA report identifies which facts AI gets wrong; fixing the cited sources that carry the misaligned claims is the primary action. Negative sentiment frequently resolves with the facts.
Aligned but Unseen (low MV, high MA). The accuracy foundation is in place; the primary problem is discoverability. An Undiscovered AI Wildcard or Undiscovered AI Pariah signals that the brand’s few mentions carry polarised or adverse reception, so sentiment analysis precedes amplification.
Unseen & Misaligned (low MV, low MA). Both dimensions need work, and the order matters. Attempting to build visibility before establishing an accurate baseline risks arriving at the Visible & Misaligned position at higher scale. The sensible starting point is specifying the Brand Profile precisely and building visibility from that foundation.
A brand with MV = 0 produces no mentioning cells across any engine or prompt. MA and MS are undefined, and the brand is reported as AI Absent. AI Absent carries no reception root and no position prefix; it sits outside the Visibility-Alignment map entirely. It is the starting condition for most brands entering AI measurement for the first time.
To see the states in practice, consider two brands in the same category. A brand with high visibility but low alignment and negative sentiment sits in the upper-left quadrant: it appears frequently in AI responses but is described inaccurately and spoken of poorly. Its designation is Misrepresented AI Pariah. Buyers who encounter that brand in an AI answer get an inaccurate, unfavourable picture; it is unlikely to appear on a shortlist for product or service evaluation. By contrast, a brand with high visibility, high alignment, and mixed sentiment sits in the upper-right quadrant. Its designation is AI Wildcard: broadly visible and accurately described, but receiving both positive and negative characterisations. Mixed sentiment does not remove a brand from consideration; a brand that polarises opinion can still make a shortlist as a potential option worth evaluating, and its path to improvement is sentiment work rather than fact correction.
How to cite
Aiviara Research. (2026). The Generative Brand Mention Framework: A Practitioners Guide. https://aiviara.com/research/gbmf-practitioners-guide/